The DocBank Dataset
DocBank is a new large-scale dataset that is constructed using a weak supervision approach. It enables models to integrate both the textual and layout information for downstream tasks. The current DocBank dataset totally includes 500K document pages, where 400K for training, 50K for validation and 50K for testing.
Here are Example annotations of the DocBank.
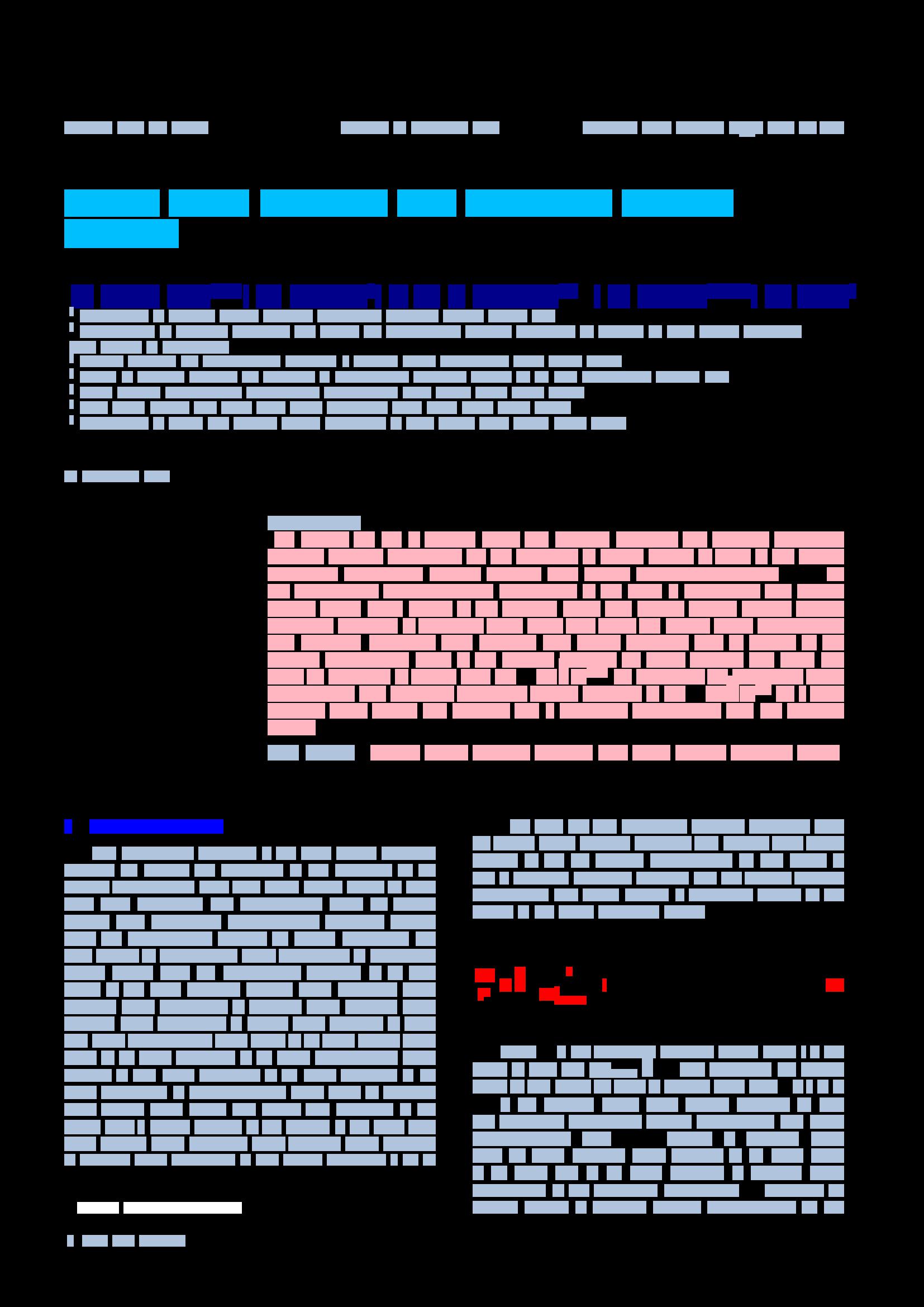
|

|

|
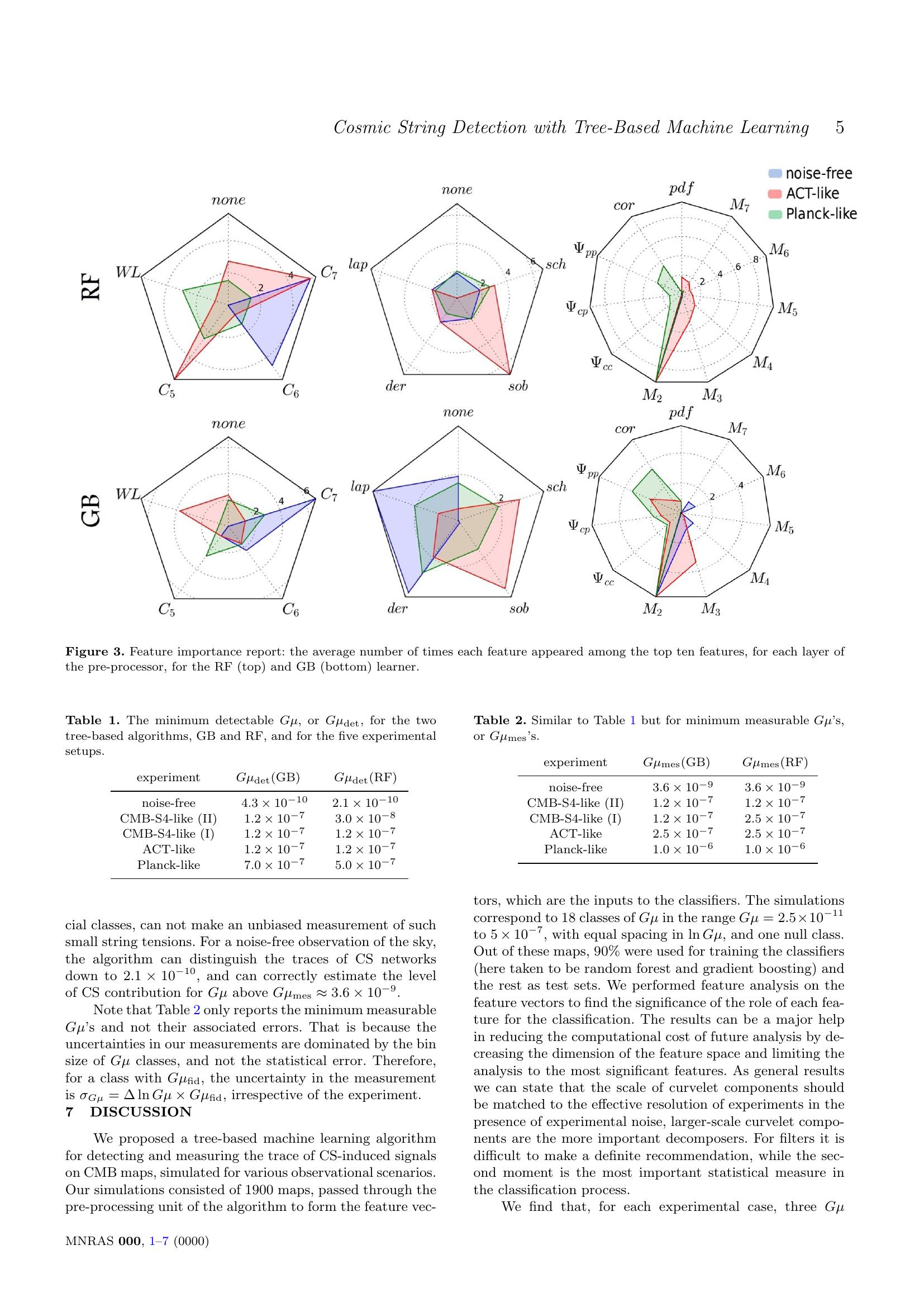
|
The colors of semantic structure labels are:
| Abstract | Author | Caption | Equation | Figure | Footer | List | Paragraph | Reference | Section | Table | Title |
DocBank is a natural extension of the TableBank (repo, paper) dataset.
LayoutLM (repo, paper) is an effective pre-training method of text
and layout and archives the SOTA result on DocBank.
For more details, please refer to our GitHub page: https://github.com/doc-analysis/DocBank.
Download
In order to reduce the loss caused by download interruption, we divided "DocBank_500K_ori_img.zip" into 10 parts, and after downloading all of them, use the decompression software to decompress them together.| File | Size | md5sum |
|---|---|---|
| DocBank_500K_txt.zip | 3,167,771,976B (2.95GB) | f1e37183d43709b44b334385684fc343 |
| DocBank_500K_ori_img.zip [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] |
50,907,670,187B (47.4GB) | - |
| MSCOCO_Format_Annotation.zip | 208,973,824B (199 MB) | 02b77f1eed22a576bd0eef660823d511 |
Annotation Format
Each line contains a token and the following information of it:
- bounding box ((x0, y0), (x1, y1)) - > (x0, y0, x1, y1)
- color (R, G, B)
- font
- label
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Content | token | x0 | y0 | x1 | y1 | R | G | B | font name | label |
Citation
If you use this dataset, please cite our paper:
DocBank: A Benchmark Dataset for Document Layout Analysis
Minghao Li, Yiheng Xu, Lei Cui, Shaohan Huang, Furu Wei, Zhoujun Li, Ming Zhou
Bibtex format:
@misc{li2020docbank,
title={DocBank: A Benchmark Dataset for Document Layout Analysis},
author={Minghao Li and Yiheng Xu and Lei Cui and Shaohan Huang and Furu Wei and Zhoujun Li and Ming Zhou},
year={2020},
eprint={2006.01038},
archivePrefix={arXiv},
primaryClass={cs.CL}
}